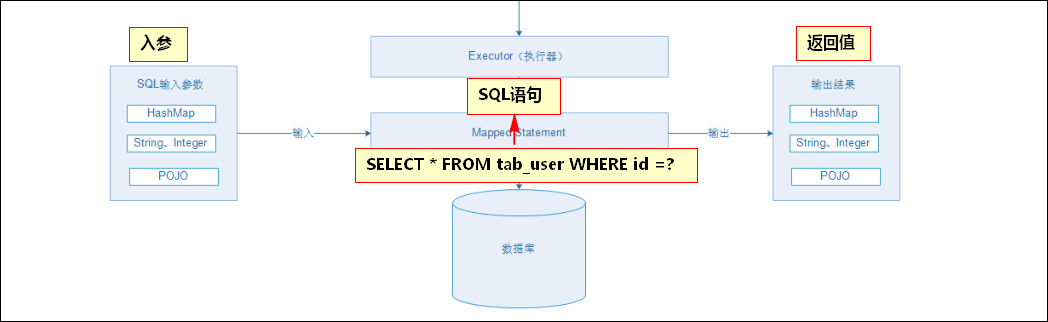
mybatis映射文件配置 1、传入的参数 【1】parameterType CRUD标签都有一个属性parameterType,底层的statement通过它指定接收的参数类型。入参数据有以下几种类型:HashMap,基本数据类型(包装类),实体类;
1 设置传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数类型。
说明:
在mybatis中入参的数据类型分为2种:
简单数据类型:int,string,long,Date;
复杂数据类型:类(JavaBean)和Map;
说明:如果传递参数是数组或者集合,底层都会封装到Map集合中。
【示例】
1 2 3 4 public interface UserMapper { User queryById (Integer id) ; }
1 2 3 4 5 6 7 8 9 10 11 【基本类型数据】 <select id ="queryById" resultType ="user" parameterType ="int" > select * from user where id = #{id} </select > 【pojo类型】 <insert id ="savetUser" parameterType ="User" > INSERT INTO user(...) </insert >
说明:对于parameterType属性可以不书写,那么MyBatis 就会通过类型处理器(TypeHandler) 根据接口中的方法User queryById(Integer id)参数类型推断出具体传入语句的参数类型。
【2】自增主键回填(了解) 【需求】
1 新增一条数据成功后,将这条数据的主键封装到实体类中,并查看主键的值。
【实现】
测试类代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void saveUser () throws Exception { User user = new User (); user.setUsername("蔡徐坤" ); user.setBirthday(new Date ()); user.setSex("男" ); user.setAddress("上海" ); userMapper.saveUser(user); System.out.println(user.getId()); }
直接获取的结果是null。
有两种方式可以实现添加好数据直接将主键封装到实体类对象中,如下:
实现一:使用insert标签的子标签selectKey实现;(自学,了解,使用不多)
属性
说明
keyColumn
主键在表中对应的列名
keyProperty
主键在实体类中对应的属性名
resultType
主键的数据类型
order
BEFORE:会首先选择主键,设置 keyProperty 然后执行插入语句
【映射文件】
mysql中的函数:last_insert_id() 得到最后添加的主键
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <insert id ="saveUser" parameterType ="user" > insert into user values (null,#{username},#{birthday},#{sex},#{address}) <selectKey keyColumn ="id" keyProperty ="id" resultType ="int" order ="AFTER" > select last_insert_id() </selectKey > </insert >
测试代码
通过getId()得到新增的主键值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void saveUser () throws Exception { User user = new User (); user.setUsername("蔡徐坤" ); user.setBirthday(new Date ()); user.setSex("男" ); user.setAddress("上海" ); userMapper.saveUser(user); System.out.println(user.getId()); }
实现二:使用insert标签的属性useGeneratedKeys,keyProperty,keyColumn实现;
属性
说明
useGeneratedKeys
true 获取自动生成的主键,相当于select last_insert_id()
keyColumn
表中主键的列名
keyProperty
实体类中主键的属性名
映射文件
1 2 3 <insert id ="saveUser" useGeneratedKeys ="true" keyColumn ="id" keyProperty ="id" > insert into user values (null ,#{username},#{birthday},#{sex},#{address}) </insert >
说明:直接在insert标签中增加属性的方式,只适合于支持自动增长主键类型的数据库,比如MySQL或SQL Server。
小结
添加用户使用哪个标签?
insert
得到主键值有哪两种方式?
子标签:selectKey
在insert中添加属性
在mysql中得到主键的函数: last_insert_id()
【3】单个参数,多个参数(重点) 主要是针对简单类型的数据(int,string,long,Date)等数据进行入参处理。
【单个参数】 【接口传参】 1 User queryById (Integer id) ;
【接收参数】 1、通过#{参数名}接收
1 2 3 4 <select id ="queryById" resultType ="User" parameterType ="int" > select *,user_name AS userName from user where id = #{id} </select >
2、通过#{任意变量名}接收
1 2 3 4 <select id ="queryById" resultType ="User" parameterType ="int" > select *,user_name AS userName from user where id = #{abc} </select >
【结论】 1 当接口方法传入一个参数时,mybatis不做特殊处理,只需要#{任意变量名}都可接收;
【多个参数】 需求:根据用户名和性别查询用户
【接口传参】 1 2 User queryByUserNameAndSex (String userName, String sex) ;
【UserMapper.xml】
1 2 3 <select id ="queryByUserNameAndSex" resultType ="User" > select * from user where username=#{username} and sex=#{sex} </select >
【测试类】
1 2 3 4 5 @Test public void queryByUserNameAndSex () throws Exception { User user = userMapper.queryByUserNameAndSex("孙悟空" , "男" ); System.out.println("user = " + user); }
【结果】
上述报异常了,当传入多个参数时,mybatis底层进行了处理。我们需要按照如下几种方式解决异常:
【接收参数】 1、使用参数索引获取:arg0,arg1 (了解)
1 2 3 4 <select id ="queryByUserNameAndSex" resultType ="User" > select * from user where username=#{arg0} and sex=#{arg1} </select >
说明:
这里的sql语句的参数书写顺序:select * from user where username=#{arg0} and sex=#{arg1}
和User user = userMapper.queryByUserNameAndSex(“孙悟空”, “男”); 传递实参顺序一致。
也就是说:username=#{arg0} —》arg0的值是姓名孙悟空。
sex=#{arg1}—》arg1的值是性别男。
2、使用参数位置获取:param1,param2 (了解)
1 2 3 4 <select id ="queryByUserNameAndSex" resultType ="User" > select * from user where username=#{param1} and sex=#{param2} </select >
3、使用命名参数获取,明确指定传入参数的名称: (掌握)
步骤一:在接口中传入参数时通过@Param指定参数名称
1 2 User queryByUserNameAndSex (@Param("username") String userName, @Param("sex") String sex) ;
步骤二:在接收参数时,通过指定的名称获取参数值;
1 2 3 4 5 <select id ="queryByUserNameAndSex" resultType ="User" > select * from user where username=#{username} and sex=#{sex} </select >
【小结】 1 2 3 4 5 6 7 8 9 1、传入多个参数时,mybatis底层处理 ,先放到一个Object数组中,然后放到了Map集合中, Object[] == > Map<Key,Value> key-param1 key-username Key值为:param1,param2...... Value值为具体的内容; 2、多个参数的取值方式: 参数索引:#{arg0} #{arg1} 参数位置:#{param1} #{param2} 命名参数:#{参数名} 3、无论使用的是单个参数还是多个参数,建议都使用命名参数进行传值;
【4】pojo参数【重点】 接口添加方法:
1 2 void saveUser (User user) ;
映射文件:
1 2 3 4 <insert id ="saveUser" > insert into user values (null ,#{username},#{birthday},#{sex},#{address}) </insert >
说明:接口方法传入pojo类型的数据时,mybatis底层直接使用pojo封装数据。 sql语句中 #{username}取值==》到pojo中调用 getUsername(){}
测试:
1 2 3 4 5 6 7 8 9 @Test public void saveUser () throws Exception { User user = new User (); user.setUsername("蔡徐坤" ); user.setBirthday(new Date ()); user.setSex("男" ); user.setAddress("上海" ); userMapper.saveUser(user); }
【5】HashMap参数 需求:模拟用户登录,登录方法参数是Map集合,泛型都是String类型分别表示用户名和性别。
在UserMapper接口中添加以下方法:
1 2 3 4 5 User login (Map<String,String> map) ;
UserMapper配置文件:
1 2 3 4 5 6 <select id ="login" resultType ="User" > select * from user where username=#{username} and sex=#{sex} </select >
测试用例:
1 2 3 4 5 6 7 8 @Test public void login () { Map<String, String> map = new HashMap <>(); map.put("username" ,"孙悟空" ); map.put("sex" ,"男" ); User user = userMapper.login(map); System.out.println(user); }
注意事项:
1 参数map中的key值是与SQL语句中 #{} 的取值名称一致。
【6】入参小结:接口方法传入的参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 mybatis中能够接收2 种类型的参数传入: 【1 】基本类型数据: 单个数据: queryById(Integer id); mybatis底层不做处理,使用任意变量都可接收 #{abc} 多个数据: queryByUsernameAndSex(@Param("username") String username,@Param("sex") String sex); mybatis底层: 第一步:把多个参数存储进数组最后放到集合map中,Map{arg0,arg1} #{arg0} #{arg1} 第二步:把数组中的数据转入Map中: username参数: param1-白骨精 username-白骨精 多个参数sql取值: #{param1} #{param2} #{username} 最佳实践: 使用命名参数取值 queryByUsernameAndSex(@Param("username") String username); sql取值: #{username} **** 【2 】复杂数据类型: 1. pojo类型数据:mybatis底层直接使用pojo封装数据 sql取值: #{pojo的属性名}**** #{username}==>调用pojo的 getUsername(){} 2. map集合数据:mybatis底层直接使用map封装参数 Map<String,String> put ("username" ,"白骨精" ) #{username}****
2、参数值的获取
说明:我们上述一直在讲解接口中的方法传入的参数,那么接下来我们要讲解如何在sql语句中获取传入的数据,其实我们之前也在一直使用一种方式就是**#{}**的方式。
参数值的获取指的是,statement获取接口方法中传入的参数。获取参数,有两种方式:**#{}和 ${}**;
【1】#{}和${}取值 #{} 取值:
mybatis后台处理:
${} 取值:
mybatis后台处理:
【接口方法】
1 2 User queryById (@Param("id") Integer id) ;
【测试类】
1 2 3 4 5 6 @Test public void queryById () throws Exception { User user = userMapper.queryById(1 ); System.out.println("user = " + user); }
【注意】${id} 获取id值时,必须使用命名参数取值:
如果不使用命名参数取值,即不在接口中加入@Param(“id”),就会报异常:
【小结】
1 2 3 4 5 6 7 8 9 10 11 1、SQL语句中获取参数的方式: #{xxx} sql:select * from user where id = ? ${xxx} sql:select * from user where id = 1 2、取值的相同点: 都能够获取接口方法传入的参数值 3、取值的不同点: #{}取值:是以预编译的形式将参数设置到SQL语句中。PreparedStatement 防止SQL注入; ${}取值:直接把获取到的参数值,拼接到sql语句中,会有安全问题;不能防止SQL注入; 4、小结: SQL传入参数的获取使用#{}; 拼接参数使用${};
【2】${}取值的应用场景 在一些特殊的应用场景中,需要对SQL语句部分(不是参数)进行拼接,这个时候就必须使用${}来进行拼接,不能使用#{}.例如:
1 2 3 4 5 6 7 8 1、企业开发中随着数据量的增大,往往会将数据表按照年份进行分表,如:2017_user,2018_user....,对这些表进行查询就需要动态把年份传入进来,而年份是表名的一部分,并不是参数,JDBC无法对其预编译,所以只能使用${}进行拼接: SELECT * FROM ${year}_user; 2、根据表名查询数据总记录数: SELECT COUNT(*) FROM user SELECT COUNT(*) FROM order SELECT COUNT(*) FROM ${tableName} 简言之:如果需要设置到SQL中的不是查询的条件,只能使用${}拼接;
示例:
需求:查询user表中的总记录数。
【映射文件】:
1 2 3 <select id ="selectCountByTableName" resultType ="int" > select count(*) from ${tableName} </select >
【接口】:
1 2 int selectCountByTableName (@Param("tableName") String table) ;
【测试类】
1 2 3 4 5 @Test public void selectCountByTableName () { int count = userMapper.selectCountByTableName("user" ); System.out.println("count = " + count); }
小结:
1 2 3 4 SQL中非参数部分的拼接使用${} 举例: select * from user where username=#{username} and sex=#{sex} 这里 #{username} #{sex} 都属于参数部分,所以是#{} select count(*) from ${tableName} 这里${tableName} 属于表名,不是参数部分,所以使用${}
【3】${}取值注意事项 【 ${}获取单个值】 了解
`${}` 获取单个值时,最好是通过命名参数的形式获取。如果不指定参数的,也可以使用${value}来获取传入的单个值;
传入参数:没有指定参数名称
获取参数:通过${value获取}
【${}获取配置文件中的值】
有时候,我们如果非要使用$来接收参数,将login修改如下:
1 2 3 4 <select id ="queryByUserNameAndSex" resultType ="User" > SELECT * FROM user WHERE user_name = '${username}' AND sex = #{sex} </select >
说明:上述sql语句中:SELECT * FROM user WHERE user_name = ‘${username}’ AND sex = #{sex}
对于 ‘${username}’ 加单引号是因为${}获取数据的方式直接将获取的数据拼接到字符串上,并不会加引号,如果获取的值是数值型,没有问题,但是如果是字符类型就会有问题,所以需要加上引号进行拼接。
假设${username}获取的值是锁哥,那么不加单引号效果是:
1 2 3 SELECT * FROM user WHERE user_name = 锁哥 AND sex = #{sex} 显然是不可以的,而加上单引号效果就是: SELECT * FROM user WHERE user_name = '锁哥' AND sex = #{sex}
测试方法:
1 2 3 4 5 @Test public void queryByUserNameAndPassword ( ) { User user = userMapper.queryByUserNameAndSex("孙悟空" , "男" ); System.out.println("user = " + user); }
执行测试: 发现测试方法中传递的参数明明是孙悟空,却获取到了jdbc.properties资源文件中的root.
原因: $可以获取资源文件中的数据,比如mybatis-config.xml中使用$获取连接信息就是。
1 <property name="driver" value="${driver}"/>
由于映射文件中使用的${username}的参数名称正好和资源文件jdbc.properties中的key相同,因此获取到了资源文件中的数据。
这种错误发生的根本原因是因为资源文件中的key和参数名称重名了,为了解决这个文件,我们只需要将资源文件中的key设置成唯一的不会被重复的key即可。
解决方案:在资源文件中的key中添加前缀
修改资源文件:
1 2 3 4 jdbc.driverClass =com.mysql.jdbc.Driver jdbc.url =jdbc:mysql://localhost:3306/heima37 jdbc.username =root jdbc.password =root
修改mybatis-config.xml:
1 2 3 4 5 6 7 <dataSource type ="POOLED" > <property name ="driver" value ="${jdbc.driverClass}" /> <property name ="url" value ="${jdbc.url}" /> <property name ="username" value ="${jdbc.username}" /> <property name ="password" value ="${jdbc.password}" /> </dataSource >
【小结】 1 2 3 4 5 6 7 8 9 10 1、#{}和${}取值的相同点: 都能够获取传入的命名参数 2、#{}和${}取值的不同点: #{}: 以预编译的方式将参数设置到sql语句中 防止SQL注入 。可以自动加单引号 ${}: 把参数直接拼接到sql语句中 不能够防止sql注入。不能自动加单引号。 3、具体应用: #{}获取sql语句中的条件参数 ${}应用于sql语句拼接和读取配置文件
扩展 mysql自带函数concat拼接使用 UserMapper接口
1 2 3 4 5 6 7 8 9 public interface UserMapper { List<User> queryUsersByAddressLike (@Param("address") String address) ; }
UserMapper.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <select id ="queryUsersByAddressLike" resultType ="User" > select * from user where address like concat('%',#{address},'%') </select >
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test public void queryUsersByAddressLike () throws Exception { SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> list = mapper.queryUsersByAddressLike("海" ); System.out.println("list = " + list); sqlSession.close(); }
入参总结: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 mybatis中能够接收2 种类型的参数传入: 【1 】基本类型数据: 单个数据: queryById(Integer id); mybatis底层不做处理,使用任意变量都可接收 #{abc} 多个数据: queryByUsernameAndSex(@Param("username") String username,@Param("sex") String sex); mybatis底层: 第一步:把多个参数存储进数组最后放到集合map中,Map{arg0,arg1} #{arg0} #{arg1} 第二步:把数组中的数据转入Map中: username参数: param1-白骨精 username-白骨精 多个参数sql取值: #{param1} #{param2} #{username} 最佳实践: 使用命名参数取值 queryByUsernameAndSex(@Param("username") String username); sql取值: #{username} **** 【2 】复杂数据类型: 1. pojo类型数据:mybatis底层直接使用pojo封装数据 sql取值: #{pojo的属性名}**** #{username}==>调用pojo的 getUsername(){} 2. map集合数据:mybatis底层直接使用map封装参数 Map<String,String> put ("username" ,"白骨精" ) #{username}**** 【3 】#{}和${}取值的相同点: 都能够获取传入的命名参数 【4 】#{}和${}取值的不同点: #{}: 以预编译的方式将参数设置到sql语句中 防止SQL注入 。可以自动加单引号 ${}: 把参数直接拼接到sql语句中 不能够防止sql注入。不能自动加单引号。 【5 】具体应用: #{}获取sql语句中的条件参数 ${}应用于sql语句拼接和读取配置文件 【6 】如果避免sql注入,并且还是sql的拼接,解决方案: 此时可以使用mysql自带函数,拼接函数:concat(数值1 ,数值2 ,数值3 ,....) 可以将concat函数中的数据拼接为一个值 举例:concat('%' ,'锁哥' ,'%' )===》结果是'%锁哥%' concat('%' ,#{userName},'%' ) ===>假设#{userName}获取的值是 喆===》'%喆%' select * from user where user_name like concat ('%' ,#{userName},'%' )
3、结果映射 我们已经学习了入参和获取参数的方式,接下来学习最后的返回值。
1 在使用原生的JDBC操作时,对于结果集ResultSet,需要手动处理。mybatis框架提供了resultType和resultMap来对结果集进行封装。
注意:只要一个方法有返回值需要处理,那么 resultType和resultMap必须有一个
【1】resultType 1 从sql语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。可以使用 resultType 或 resultMap,但不能同时使用。
1.1返回值是简单类型 例如 int ,string ===>resultType=”书写对应的基本类型别名或者全名即可”
1.2返回值为一个pojo(User)对象时 【定义resultType为User】
【使用User来接收返回值】
1.3返回值为一个List时 当返回值为List集合时,resultType需要设置成集合中存储的具体的pojo数据类型:
【映射文件】
【接口】
【测试类】
1 2 3 4 5 6 List<User> userList = mapper.findAllUsers(); for (User user : userList) { System.out.println(user); }
1.4返回值为map 【1】返回一条数据,封装到map中 需求:查询id是1的数据,将查询的结果封装到Map<String,Object>中
接口方法:
1 2 Map<String,Object> selectByIdReturnMap (Integer id) ;
SQL语句:
1 2 3 <select id ="selectByIdReturnMap" resultType ="map" > select * from user where id=#{id} </select >
测试:原来封装到对象中的数据也能够封装到map中
1 2 3 4 5 @Test public void selectByIdReturnMap () { Map<String, Object> map = userMapper.selectByIdReturnMap(1 ); System.out.println("map = " + map); }
结果:
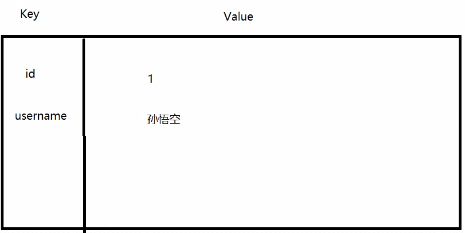
1 map = {birthday=1980 -10 -24 , address=花果山水帘洞, sex=男, id=1 , username=孙悟空}
通过上述结果我们发现如果返回一条数据放到Map中,那么列名会作为Map集合的key,结果作为Map集合的value:
【2】返回多条数据,封装到map中 需求:查询数据表所有的数据封装到Map<String,User>集合中
要求: Key值为一条记录的主键,Value值为pojo的对象.
如下所示:
接口方法:接口方法上面通过注解 @MapKey指定key值封装的列数据
1 2 3 @MapKey("id") Map<String, User> selectReturnMap () ;
说明:需要在接口的方法上使用注解@MapKey指定数据表中哪一列作为Map集合的key,否则mybatis不知道具体哪个列作为Map集合的key.
SQL语句:
1 2 3 <select id ="selectReturnMap" resultType ="map" > select * from user </select >
测试代码:
1 2 3 4 5 @Test public void selectReturnMap () { Map<String, User> map = userMapper.selectReturnMap(); System.out.println("map = " + map); }
结果:
1 2 map = {1 ={birthday=1980 -10 -24 , address=花果山水帘洞, sex=男, id=1 , username=孙悟空}, 2 ={birthday=1992 -11 -12 , address=白虎岭白骨洞, sex=女, id=2 , username=白骨精}, 3 ={birthday=1983 -05 -20 , address=福临山云栈洞, sex=男, id=3 , username=猪八戒}, 4 ={birthday=1995 -03 -22 , address=盤丝洞, sex=女, id=4 , username=蜘蛛精}, 7 ={birthday=2020 -06 -05 , address=上海, sex=男, id=7 , username=蔡徐坤}, 8 ={birthday=2020 -06 -05 , address=上海, sex=男, id=8 , username=蔡徐坤}, 9 ={birthday=2020 -06 -05 , address=上海, sex=男, id=9 , username=蔡徐坤}, 10 ={birthday=2020 -06 -05 , address=上海, sex=男, id=10 , username=蔡徐坤}, 11 ={birthday=2020 -06 -06 , address=上海, sex=男, id=11 , username=蔡徐坤}}
小结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1. 接口方法返回类型是简单类型(除了单列集合),那么在标签的resultType属性值中书写返回简单类型的类名或者别名 举例: Integer show () ;====> resultType="int" String show () ;====> resultType="string" 2. 如果接口方法返回类型是简单类型的单列集合,那么在标签的resultType属性值中书写集合的泛型类型 举例: List<User> show () ;====> resultType="User" 3. 如果接口方法返回类型是复杂类型的pojo,那么在标签的resultType属性值中书写pojo类型 举例: User show () ;====> resultType="User" 4. 如果接口方法返回类型是复杂类型的Map,那么在标签的resultType属性值中书写map类型,但是分为返回的是单行数据还是多行数据: 如果是单行数据,不用做处理 如果是多行数据,在方法上使用注解@MapKey("数据表字段名") 告知mybatis,哪个字段名的值作为map集合的key 举例: 如果是多行数据 @MapKey("id") Map<Integer,Object> show () ;
【2】resultMap(掌握) ResultMap是mybatis中最重要最强大的元素,使用ResultMap可以解决两大问题:
POJO属性名和表结构字段名不一致的问题(有些情况下也不是标准的驼峰格式,比如id和userId)
完成高级查询,比如说,一对一、一对多、多对多。(后面多表中会涉及到)
查询数据的时候,查不到userName的信息,原因:数据库的字段名是user_name,而POJO中的属性名字是userName解决方案1 :在sql语句中使用别名
1 2 3 <select id ="queryById" resultType ="user" parameterType ="int" > select *,name as username from user where id = #{id} </select >
解决方案2 :参考驼峰匹配 — mybatis-config.xml 的时候
1 2 3 <settings > <setting name ="mapUnderscoreToCamelCase" value ="true" /> </settings >
注意:这种解决方案只能解决列名是下划线命名.
解决方案3 :resultMap自定义映射
通过案例掌握resultMap的使用方式之一,手动配置实体类中属性和表中字段的映射关系
【需求】 1 使用resultMap完成结果集的封装(resultSet===》JavaBean)
【实现步骤】 1 2 3 4 手动配置实体类属性和表字段映射关系的步骤如下: 1、 配置自定义结果集<resultMap > 2、 配置id映射 3、 配置其他普通属性的映射
步骤一: 将驼峰匹配注释掉
步骤二: 配置resultMap
resultMap标签的作用:自定义结果集,自行设置结果集的封装方式
1 2 3 id属性:resultMap标签的唯一标识,不能重复,一般是用来被引用的 type属性:结果集的封装类型 autoMapping属性:操作单表时,不配置默认为true,如果pojo对象中的属性名称和表中字段名称相同,则自动映射。
在映射文件中自定义结果集类型:
1 2 3 4 5 6 7 8 9 <resultMap id ="userResultMap" type ="User" autoMapping ="true" > <id column ="id" property ="id" > </id > <result column ="name" property ="username" > </result > </resultMap >
步骤三 :修改查询语句的statement
1 2 3 4 5 6 <select id ="queryById" resultMap ="userResultMap" > select * from user where id = #{id} </select >
测试代码:
1 2 3 4 5 6 @Test public void queryById () throws Exception { User user = userMapper.queryById(1 ); System.out.println("user = " + user); }
注意: 测试完记得将驼峰命名的配置重新开启,因为其他的测试方法还要用。
【小结】 resultMap可以用来手动配置属性和字段的映射关系:
属性:
1 2 3 4 5 6 7 8 9 1、id属性 定义唯一标识,用来被sql语句的声明引用的 2、type属性 配置结果集类型,将查询的数据往哪个类型中封装 3、autoMapping属性的值 为true时:在字段和属性名称相同时,会进行自动映射。如果不配置,则默认为true。 为false时:只针对resultMap中已经配置的字段作映射。
子标签:
1 2 3 4 1、id子标签 配置主键的映射关系 2、result子标签 配置其他普通属性和字段的映射关系
4、动态SQL MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
例如,下面需求就会使用到拼接sql语句:
【需求】:查询男性 用户,如果输入了用户名,按用户名模糊查询 ,如果没有输入用户名,就查询所有男性用户 。
正常的sql语句:查询男性并且用户名中包含zhang
1 select * from tb_user where sex = "男" and user_name like '%zhang%'
1 select * from tb_user where sex = "男"
实现需求时还要判断用户是否输入用户名来做不同的查询要求,而这里似乎没有办法判断是否输入了用户名,因此可以考虑使用动态sql来完成这个功能。
动态 SQL 元素和后面学习的 JSTL 或基于之前学习的类似 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多元素需要花时间了解。MyBatis 3 开始精简了元素种类,现在只需学习原来一半的元素便可。MyBatis 采用功能强大的 OGNL 的表达式来淘汰其它大部分元素。
常见标签如下:
1 2 3 4 if:判断 if(1 gt 2){} choose (when, otherwise):分支判断 switch:多选一 trim (where, set):去除 foreach:循环遍历标签
动态SQL中的业务逻辑判断需要使用到以下运算符: ognl表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. e1 or e2 满足一个即可 2. e1 and e2 都得满足 3. e1 == e2,e1 eq e2 判断是否相等 4. e1 != e2,e1 neq e2 不相等 5. e1 lt e2:小于 lt表示less than 6. e1 lte e2:小于等于,其他gt(大于),gte(大于等于) gt 表示greater than 7. e1 in e2 8. e1 not in e2 9. e1 + e2,e1 * e2,e1/e2,e1 - e2,e1 10. !e,not e:非,求反 11. e.method(args)调用对象方法 12. e.property对象属性值 13. e1[ e2 ]按索引取值,List,数组和Map 14. @class@method(args)调用类的静态方法 15. @class@field调用类的静态字段值
1、if标签 格式:
1 2 3 4 5 6 <if test ="判断条件" > 满足条件执行的代码 </if > 说明: 1)if标签:判断语句,用于进行逻辑判断的。如果判断条件为true,则执行if标签的文本内容 2)test属性:用来编写表达式,支持ognl;
【需求】:查询男性 用户,如果输入了用户名,按用户名模糊查询 ,如果没有输入用户名,就查询所有男性用户 。
正常的sql语句:查询男性并且用户名中包含zhang
1 select * from tb_user where sex = "男" and user_name like '%zhang%'
1 select * from tb_user where sex = "男"
实现需求时还要判断用户是否输入用户名来做不同的查询要求,而这里似乎没有办法判断是否输入了用户名,因此可以考虑使用动态sql来完成这个功能。
上述动态sql语句部分: and user_name like '%zhang%'
1.1、定义接口方法 在UserMapper接口中,定义如下方法:
1 2 3 4 5 6 List<User> queryLikeUserName (@Param("userName") String userName) ;
1.2、编写SQL 在UserMapper.xml文件中编写与方法名同名的sql语句:
1 2 3 4 5 6 <select id ="queryLikeUserName" resultType ="user" > select * from user where sex='男' <if test ="userName!=null and userName.trim()!=''" > and username like '%${userName}%' </if > </select >
【注】<if> 判断中:
1、if标签:用来判断;
2、test属性:使用OGNL表达式,完成具体的判断业务逻辑;
3、这里使用的字符串拼接,所以这里不能是#取值,只能使用$取值,否则会报错
1.3、测试 【userName有值】
对应的SQL语句是:select * from user where sex=”男” and username like ‘%孙%’
【userName没有值】
对应的SQL语句是:select * from user where sex=”男”
【小结】
1 2 3 1、if标签:用来在sql中处理判断是否成立的情况; 2、属性:test中书写OGNL表达式,如果结果为true,if标签的文本中的内容会被拼接到SQL中,反之不会被拼接到SQL中; 3、if标签的应用场景:适用于 二选一
2、choose,when,otherwise 1 2 3 4 choose标签:分支选择(多选一,遇到成立的条件即停止) when子标签:编写条件,不管有多少个when条件,一旦其中一个条件成立,后面的when条件都不执行。 test属性:编写ognl表达式 otherwise子标签:当所有条件都不满足时,才会执行该条件。
需求:
1 2 3 4 5 6 编写一个查询方法,设置两个参数,一个是用户名,一个是住址。 根据用户名或者住址查询所有男性用户: 如果输入了用户名则按照用户名模糊查找, 否则就按照住址查找,两个条件只能成立一个, 如果都不输入就查找用户名为“孙悟空”的用户。
【需求分析】
1、查询所有男性用户,如果输入了用户名则按照用户名模糊查找;
1 SELECT * FROM user WHERE sex = "男" AND username LIKE '%孙%' ;
2、查询所有男性用户,如果输入了住址则按照住址查询;
1 SELECT * FROM user WHERE sex = "男" AND address = "花果山水帘洞";
3、查询所有男性用户,如果都不输入就查找用户名为“孙悟空”的用户。
1 SELECT * FROM user WHERE sex = "男" AND username = '孙悟空' ;
2.1、定义接口方法 在UserMapper接口中,定义接口方法:
1 2 3 4 List<User> queryByUserNameOrAddress (@Param("userName") String userName, @Param("address") String address) ;
2.2、编写SQL 在UserMapper.xml中编写对应的SQL语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <select id ="queryByUserNameOrAddress" resultType ="user" > select * from user where sex='男' <choose > <when test ="userName!=null and userName.trim()!=''" > and username like '%${userName}%' </when > <when test ="address!=null and address.trim()!=''" > and address = #{address} </when > <otherwise > and username='孙悟空' </otherwise > </choose > </select >
2.3、测试 编写测试类,对这个方法进行测试:
1 2 3 4 5 @Test public void queryByUserNameOrAddress () { List<User> userList = userMapper.queryByUserNameOrAddress("" , null ); System.out.println("userList = " + userList); }
【小结】
1 1、choose,when,otherwise标签组合的作用类似于java中的switch语句,使用于多选一;
3、where where标签:拼接多条件查询时 1、能够添加where关键字; 2、能够去除多余的and或者or关键字
案例:按照如下条件查询所有用户,
1 2 3 如果输入了用户名按照用户名进行查询, 如果输入住址,按住址进行查询, 如果两者都输入,两个条件都要成立。
【需求分析】
1、如果输入了用户名按照用户名进行查询,
1 SELECT * FROM user WHERE user_name = '孙悟空' ;
2、如果输入住址,按住址进行查询,
1 SELECT * FROM user WHERE address= '花果山水帘洞' ;
3、如果两者都输入,两个条件都要成立。
1 SELECT * FROM user WHERE user_name = '孙悟空' AND address= '花果山水帘洞' ;
3.1、定义接口方法 在UserMapper接口中定义如下方法:
1 List<User> queryByUserNameAndAge (@Param("userName") String userName, @Param("address") String address) ;
3.2、编写SQL 在UserMapper.xml中编写SQL
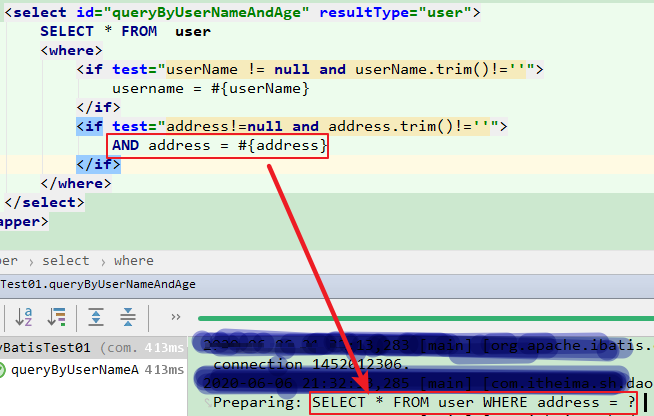
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <select id ="queryByUserNameAndAge" resultType ="user" > SELECT * FROM user <where > <if test ="userName != null and userName.trim()!=''" > username = #{userName} </if > <if test ="address!=null and address.trim()!=''" > AND address = #{address} </if > </where > </select >
说明:
1.说明:如果按照如下写sql语句会有问题,假设用户名username是空,那么用户名的sql语句不参与条件,此时
2.SELECT * FROM user WHERE address = ?
3.3、测试 1 2 3 4 5 @Test public void queryByUserNameAndAge () { List<User> userList = userMapper.queryByUserNameAndAge("" , "花果山水帘洞" ); System.out.println("userList = " + userList); }
只传入住址,此时where子标签去掉了and.
【小结】
1 2 1、<where>标签作用:用于拼接多选一或者同时成立的SQL情况; 2、<where>还会根据情况,动态的去掉SQL语句中的AND或者or;
4、set set标签:在update语句中,可以自动添加一个set关键字,并且会将动态sql最后多余的逗号去除。
案例:修改用户信息,如果参数user中的某个属性为null,则不修改。
如果在正常编写更新语句时,如下:
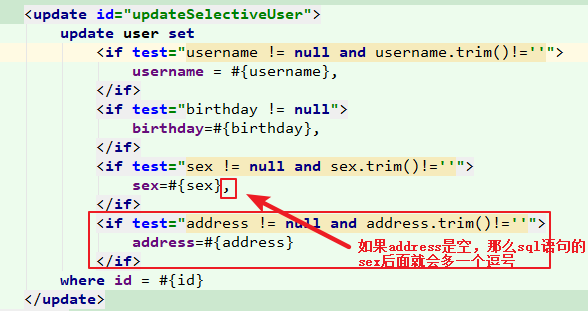
1 update user SET username = ?, birthday= ?, sex= ?, where id = ?
那么一旦在传递的参数中没有address,此时生成的sql语句就会因为多了一个逗号而报错。
4.1、定义接口方法 在UserMapper接口中定义如下方法:
1 void updateSelectiveUser (User user) ;
4.2、编写SQL 在UserMapper.xml文件中编写如下SQL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <update id ="updateSelectiveUser" > update user <set > <if test ="username != null and username.trim()!=''" > username = #{username}, </if > <if test ="birthday != null" > birthday=#{birthday}, </if > <if test ="sex != null and sex.trim()!=''" > sex=#{sex}, </if > <if test ="address != null and address.trim()!=''" > address=#{address} </if > </set > where id = #{id} </update >
4.3、测试 1 2 3 4 5 6 7 8 9 10 11 @Test public void updateSelectiveUser () { User user = new User (); user.setUsername("锁哥1" ); user.setBirthday(new Date ()); user.setSex("男" ); user.setAddress("" ); user.setId(7 ); userMapper.updateSelectiveUser(user); }
【结果】
1 update user SET username = ?, birthday= ?, sex= ? where id = ?
【小结】
1 2 1、<set>标签替代了sql语句中的set关键字; 2、<set>标签还能把sql中多余的,去掉;
5、foreach 1 2 3 4 5 6 7 8 9 foreach标签:遍历集合或者数组 <foreach collection ="集合名或者数组名" item ="元素" separator ="标签分隔符" open ="以什么开始" close ="以什么结束" > #{元素} </foreach > collection属性:接收的集合或者数组,集合名或者数组名 item属性:集合或者数组参数中的每一个元素 separator属性:标签分隔符 open属性:以什么开始 close属性:以什么结束
需求:按照id值是1,2,3来查询用户数据;
5.1、定义接口方法 在UserMapper接口中定义如下方法:
1 List<User> queryByIds (@Param("arrIds") Integer[] arrIds) ;
这里一定加@Param(“arrIds”),否则报错
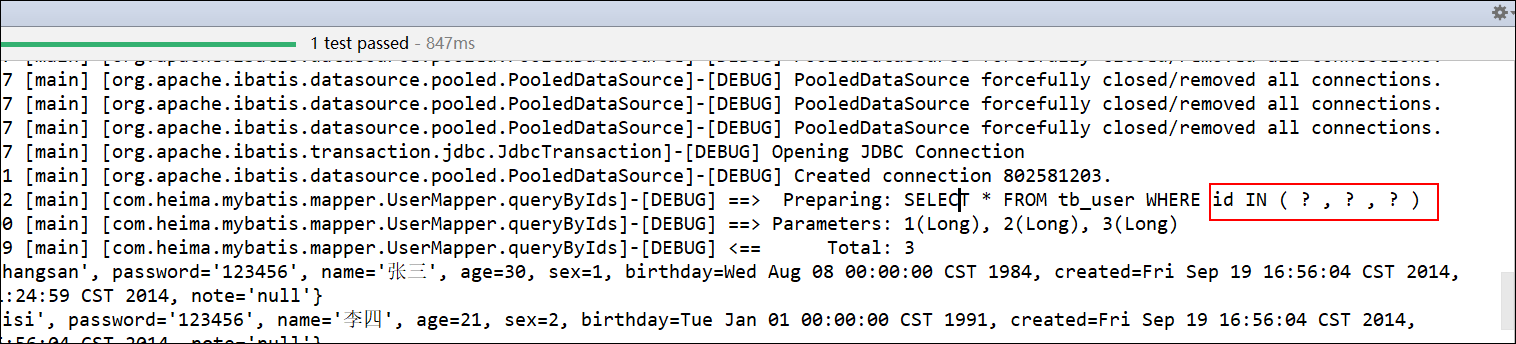
5.2、编写SQL 1 2 3 4 5 6 7 <select id ="queryByIds" resultType ="user" > SELECT * FROM user WHERE id IN <foreach collection ="arrIds" item ="ID" separator ="," open ="(" close =")" > #{ID} </foreach > </select >
5.3、测试 1 2 3 4 5 6 @Test public void queryByIds () { Integer[] arrIds = {1 ,2 ,3 }; List<User> userList = userMapper.queryByIds(arrIds); System.out.println("userList = " + userList); }
【小结】
1 <foreach>标签的作用:用于对查询参数进行遍历取值;
6、小结 1 2 3 4 5 6 7 8 9 10 11 12 13 If标签:条件判断 test属性:编写ognl表达式 where标签:用于sql动态条件拼接,添加where关键字,可以将动态sql多余的第一个and或者or去除。 set标签: 用于更新语句的拼接,添加set关键字,并可以将动态sql中多余的逗号去除 foreach标签:用于遍历参数中的数组或者集合 collection属性:参数中的数组或者集合 item属性:表示数组或者集合中的某个元素,取出数据使用# {item的属性值} separator属性:分隔符 open:以什么开始 close:以什么结束
总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 一、映射文件配置 【1】作用:配置sql相关信息 1、CRUD四类标签: 2、sql标签:sql片段 3、resultMap: 【2】CRUD四类标签: 增: <insert > </insert > 删: <delete > </delete > 改:<update > </update > 查:<select > </select > 【3】入参相关:<select resultType ="User" paramType ="int" > SELECT * FROM user WHERE id = #{id} </select > paramType:设置传入的参数的类型,可以省略 insert语句相关:自增主键回填--数据插入到数据库之后,返回这条数据在数据库中的主键值 【1】子标签:<selectKey > </selectKey > <selectKey keyColumn ="id" keyProperty ="id" resultType ="int" order ="AFTER" > SELECT LAST_INSERT_ID() ; </selectKey > 【2】属性: useGeneratedKeys="true" keyColumn="id" keyProperty="id" 【4】sql参数传入: 能够接收的参数类型: 基本类型数据,pojo,map 【5】传入基本类型数据:string,int 单个数据传入: queryById(Integer id) WHERE id = #{id} 多个数据传入:queryByNameAndSex(String name,String sex): WHERE username=#{} and sex= #{} 最佳实践:命名参数取值 queryByNameAndSex(@Param("name")String name,@Param("sex")String sex): WHERE username=#{name} and sex= #{sex} 【6】传入pojo和map数据: pojo: User{id,username} #{username} map: Map<Key,Value> #{key} 【7】映射文件中sql语句取值: #{} ${} 相同点:都能够获取命名参数值 不同点: #{} 取值使用预编译方式设置参数 ${} 直接标签获取的参数拼接到sql语句中 最佳实践: 获取查询参数,防止SQL注入 使用 #{}取值 【8】${}应用场景: 拼接SQL语句 【9】sql返回值处理: resultType:基本类型数据,pojo,map 基本类型数据: resultType="int" pojo类型: 单个pojo,多个pojo: resultType="pojo" map: 单条数据:map 默认 resulteType="map" 多条数据:map @MapKey("id") resultMap: 【1】设置数据库的列名 和 实体类的属性名之间 映射关系 【2】多表关联配置: 【10】动态sql: 判断: if,分支 trim: where,set foreach:遍历
高级查询 1、一对一查询 1 2 3 4 5 6 7 association:配置关联对象(User)的映射关系 <association property="user" javaType="User" autoMapping="true" > </association> 属性: property:关联对象在主表实体类中的属性名;property="user" 表示在Order类中的引用的User类的对象 成员变量名 javaType:关联对象的类型;javaType="User" 表示引用的user对象属于User类型
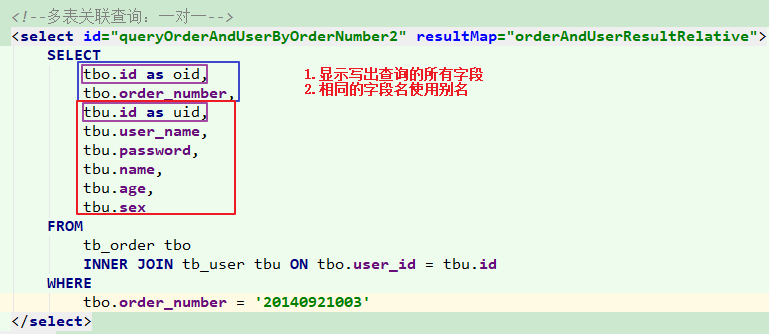
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace ="com.itheima.sh.dao.OrderMapper" > <resultMap id ="orderAndUserResultRelative" type ="Order" autoMapping ="true" > <id column ="id" property ="id" /> <association property ="user" javaType ="User" autoMapping ="true" > <id column ="id" property ="id" /> </association > </resultMap > <select id ="queryOrderAndUserByOrderNumber2" resultMap ="orderAndUserResultRelative" > SELECT * FROM tb_order tbo INNER JOIN tb_user tbu ON tbo.user_id = tbu.id WHERE tbo.order_number = #{orderNumber} </select > </mapper >
说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1 、由于queryOrderAndUserByOrderNumber2查询的结果Order对象中需要封装User信息,所以返回值不能够再使用单纯的resultType来操作;2 、定义resultMap进行关联查询的配置,其中: 属性: id:标识这个resultMap; type:返回的结果类型 autoMapping="true" : 表示只需要给当前表的id然后自动映射当前表的其他列值到对应实体类的属性中,这 属于偷懒行为,开发中我们最好都书写出来 子元素: id:主表主键映射 result:主表普通字段的映射 association:关联对象的映射配置 3 、association:配置关联对象(User)的映射关系 属性: property:关联对象在主表实体类中的属性名;property="user" 表示在Order类中的引用的User类的对象 成员变量名 javaType:关联对象的类型;javaType="User" 表示引用的user对象属于User类型
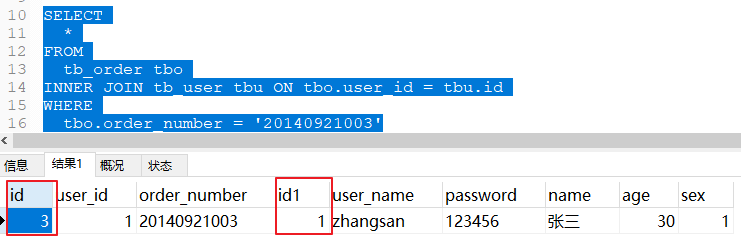
注意事项 通过上述测试结果,我们发现User的id是错误的,不是3,正确结果是1:
因为tb_user表的主键是id,tb_order的主键也是id。查询的结果中有两列相同的id字段。在将查询结果封装到实体类的过程中就会封装错误。
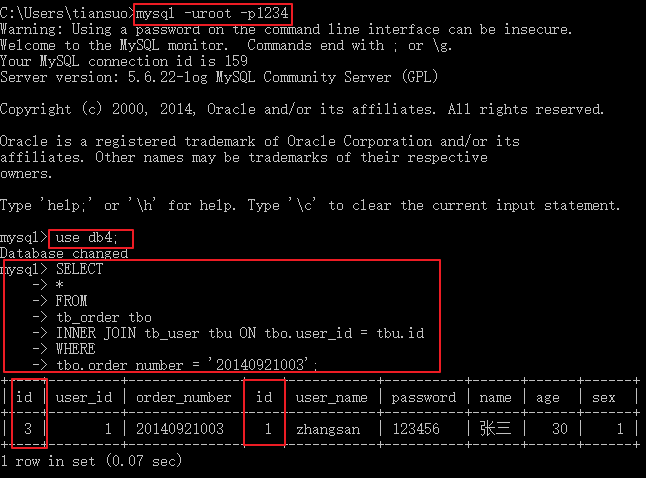
注意:user表查询的是id不是id1,由于SQLyog图形化界面显示的原因。可以在cmd窗口查看结果:
【解决方案】
1 2 1、建议将所要查询的所有字段显示地写出来; 2、将多表关联查询结果中,相同的字段名取不同的别名;
resultMap中应该如下配置:
【正确结果】
【小结】 1 2 3 4 5 6 7 8 9 10 11 12 13 一对一关联查询: 1、需要在Order实体类中关联User对象;最终将数据封装到Order中; 2、在OrderMapper.xml文件中书写关联语句并配置关系; 3、关联关系配置: <resultMap id ="orderAndUserResultRelative" type ="Order" autoMapping ="true" > <id column ="oid" property ="id" /> <association property ="user" javaType ="User" autoMapping ="true" > <id column ="uid" property ="id" /> </association > </resultMap >
2、一对多查询 在UserMapper.xml 文件中编写SQL语句完成一对多的关联查询;
说明:
1 2 3 4 5 6 7 8 1.一对多使用collection子标签进行关联多方Order <collection property ="类中引用多方的成员变量名" javaType ="存放多方容器的类型" ofType ="多方类型" autoMapping ="true" > </collection > 2.属性: 1)property="orders" 这里的orders表示User类的成员变量orders 2)javaType="List" 表示User类的成员变量orders存储的Order对象使用的类型,这里是List 一般不书写 3) ofType="Order" 表示List集合中存储数据的类型 Order 3.一定要记住这里给user表的id起别名是uid,order表的id起别名是oid.在resultMap标签的id子标签中的column属性值书写对应的uid和oid.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 <resultMap id ="oneToManyResult" type ="User" autoMapping ="true" > <id column ="uid" property ="id" /> <collection property ="orders" javaType ="List" ofType ="Order" autoMapping ="true" > <id column ="oid" property ="id" /> </collection > </resultMap > <select id ="oneToManyQuery" resultMap ="oneToManyResult" > SELECT tbo.id as oid, tbo.order_number, tbu.id as uid, tbu.user_name, tbu.password, tbu.name, tbu.age, tbu.sex FROM tb_user tbu INNER JOIN tb_order tbo ON tbu.id = tbo.user_id WHERE tbu.id = #{id} </select >
在用户的测试类中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class MybatisTest01 { private static UserMapper mapper = null ; @BeforeClass public static void beforeClass () throws Exception { String resouce = "mybatis-config.xml" ; InputStream is = Resources.getResourceAsStream(resouce); SqlSessionFactory build = new SqlSessionFactoryBuilder ().build(is); SqlSession sqlSession = build.openSession(true ); mapper = sqlSession.getMapper(UserMapper.class); } @Test public void oneToManyQuery () { User user = mapper.oneToManyQuery(1L ); System.out.println("user = " + user); } }
【小结】 1 2 3 4 一对多关系配置: 1、在对象中添加映射关系; 2、编写接口方法,编写SQL; 3、编写resultMap处理数据库字段和实体类之间数据的封装;
高级查询小结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 resutlType无法帮助我们自动的去完成映射,所以只有使用resultMap手动的进行映射 resultMap: 属性: type 结果集对应的数据类型 Order id 唯一标识,被引用的时候,进行指定 autoMapping 开启自动映射 extends 继承 子标签: id:配置id属性 result:配置其他属性 association:配置一对一的映射 property 定义对象的属性名 javaType 属性的类型 autoMapping 开启自动映射 collection:配置一对多的映射 property 定义对象的属性名 javaType 集合的类型 ofType 集合中的元素类型 泛型 autoMapping 开启自动映射